
Why I use typed functional programming
TL;DR: Functional programming languages and architectures provides many features (declarative programming; immutability; higher-order functional composition; static typing with type inference; pure functions; lazy evaluation) that offer, in my opinion, more benefits than disadvantages when compared to their imperative counterparts.
Many people, time and time again, come to me with the following question:
Sol, why do keep using these esoteric programming languages in production? If Google uses Python, shouldn’t you also use it? Or do you think you are better than Google?
So I though that I might as well write a blog post about it so every time I hear this question again I can just arrogantly send them a link to this post.
Disclaimers:
- I have little formal training in computer sciences. This material is my take on the topic and should not be used or considered as scientific (or even right).
- This is a pretty long post, intended to used more as a reference than a blog post. Proceed to read everything at your own risk.
What is functional programming?
This is a complicated question. If you ask this question to 10 functional programmers you’re probably getting 11 different answers back, but most will agree that in order to a programming language to be considered “functional” it must have the following characteristics:
- Declarative programming
- Immutability
- Higher-Order functional composition
And they also might include:
- Static type system (such as a Hindley–Milner type system) with type inference
- Pure functions
- Lazy evaluation
So let’s talk abou these characteristics and how they can help us write better software
Declarative programming
If you’re reading this post, you’re probably used to write programs in the imperative paradigm, such as in the following example:
// C
int oldArray[4] = {1, 2, 3, 4};
int newArray[4];
for (int i = 0; i < 4; i++) {
newArray[i] = oldArray[i] * 2;
}
This is a classic example of imperative programming, where the code is a sequence of instructions which dictate to the compiler what the machine should do with our program’s data step-by-step. In this example we’re stating that the machine must first create an array of integers with some given values, then create another array of the same size in which the transformed data will go, then we create a control variable called i which will be used to manage the current state of our code’s execution, then we initialize it, determine at which point the loop should be stopped and how this control variable should be updated at the end of each loop. Last we tell the compiler the origin, what it should do (multiply each element by 2) and where it should store the data for each loop.
If you read the last paragraph in it’s totality first of all congratulations, and second of all: did you notice how much boilerplate I had to write in order to describe each step of this extremely short piece of code? Even though as soon as your eyes looked at it you were able to understand what it was doing, its intent (multiply each element by 2) is buried within layers and layers of what I call ‘control code’. And everyone knows what happens if I make a simple mistake such as switching < with <=…
By this time you might be saying: ‘So what? you pick the worst programming language to give an example’, to which I’d like to reply with the following example in Python:
# Python
old_list = [1, 2, 3, 4]
new_list = []
for i in old_list:
new_list.append(i * 2)
Or we can make this code even terser:
new_list = []
for i in range(1, 5):
new_list.append(i * 2)
Edit: Many people raised the point that most python programmers would implement this code section using list comprehensions:
new_list = [i * 2 for i in range(1, 5)]
Curiously, list comprehensions were first implemented in functional languages. Also, it is very interesting to see that this form is preferable precisely due to it’s readability (exactly the point I’m trying to make in this section), since list comprehensions don’t offer any significant gains in performance.
Even though the code is “cleaner” than its first implementation, we still had to write some “control code” to express what we wanted to achieve. And if you think about it deeply, this code can be translated simply as “new list is equal to the old list with it’s values multiplied by two”. Notice that in this phrase there were no whiles, fors or any other kind of “control words”.
This is exactly the problem that the declarative programming paradigm tries to solve: instead of mixing “control code” with “intent code”, let’s just write our intents and let the compiler/interpreter figure out how to achieve them.
Here are some examples of how functional programming languages would implement the code above:
-- Haskell
oldList = [1 .. 4]
newList = map (* 2) oldList
// F#
let oldList = {1 .. 4}
let newList = Seq.map (fun x -> x * 2) oldList
// Scala
val oldList = List(1, 2, 3, 4)
val newList = oldList.map(x => x * 2)
// Clojure
(def old-list (range 1 4))
(def new-list (map #(* % 2) old-list))
Even though Cloujure’s syntax1 may get in the way of you understanding the code’s intent, even for a beginner clojurian this code’s intent is pretty obvious.
In all the examples above we’re merely stating that the new list is equal to the old list with the multiplication function applied (mapped) over each of its elements. We just tell the compiler/interpreter what whe want to be done and leave the how for the machine to figure it out.
And here generally comes the first fair criticism to functional programming languages: by writing our software in the form of expressions instead of statements we’re automatically creating a impedance mismatch (incompatibility) between our code and the execution model (von Neumann) of almost all modern day computing machines. Even though this is somewhat true for single threaded performance, in most modern functional programming languages the performance penalty is not that big and hosted languages such as F#, Scala and Clojure support interoperability with native code, so you can optimize the critical paths of your code with imperative code. For parallel execution the roles are reversed, but we’ll discuss it in the next section.
So the conclusion of this section is that I agree with most seasoned developers when they say that we spend much more time reading code than writing it, so it is my conclusion that code should be as evident and transparent as possible in it’s intent and declarative programing (therefore functional programming) help us achieve this goal more effectively and efficiently than imperative programing.
Immutability
Immutability is concept that dictates that once you bind a value to a name (equivalent to assigning a value to a variable in the imperative world), that relation can’t be broken during the program’s execution for as long as the variable is under an active scope, unless it is explicitly stated otherwise.
In order to better illustrate this concept let’s compare how a programmer would update a value in a map in a “normal” programming language and in a funcional programming language:
# Python
# In python, maps are actually called dictionaries, but let's use the term 'map'
# for simplicity's sake
original_map = {
"key1": 1,
"key2": 2,
"key3": 3,
}
original_map["key1"] = 4
print(original_map)
# output
# {'key1': 4, 'key2': 2, 'key3': 3}
The code above would result in {'key1': 4, 'key2': 2, 'key3': 3}, which is what most programmers would agree should happen. Now let’s compare it with a functional language, such as F#:
// F#
// The ;; is only necessary in F#'s REPL
let originalMap =
Map.ofList [("key1", 1); ("key2", 2); ("key3", 3)];;
Map.add "key1" 4 originalMap;;
printfn "%O" originalMap;;
// output
// map [("key1", 1); ("key2", 2); ("key3", 3)]
It may not come as a surprise, since we’re talking about immutability, but the code above would result in map [("key1", 1); ("key2", 2); ("key3", 3)].
By now you may think: “Of what use is a programming language in which I can’t even update a simple map with a new value?”, to which I reply that you don’t really need to change the original map to have a map with the new value. All you have to do is just create a new map which is a copy of the original one with the value of "key1" changed:
// F#
// The ;; is only necessary in F#'s REPL
let originalMap =
Map.ofList [("key1", 1); ("key2", 2); ("key3", 3)];;
let newMap = Map.add "key1" 4 originalMap;;
printfn "%O" newMap;;
// output
// map [("key1", 4); ("key2", 2); ("key3", 3)]
Now the code above would result in map [("key1", 4); ("key2", 2); ("key3", 3)], as we desired all along.
Now you’d say: “Well, I don’t see what is the big deal here. In fact this seems to me just a waste of memory and code”, so allow me to retort to that in the following paragraphs.
The first thing that should be clear is that functional languages optimize memory allocation with a lot of reuse, and here is how they do it: let’s represent our map as a set of references key-value pairs:
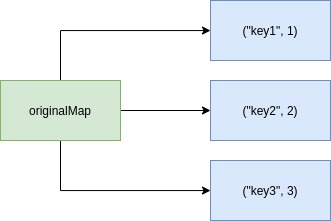
Once we tell our compiler that newMap is just the originalMap but with a new value for "key1", he will do just that, create a new map referencing the same old key-value pairs except the one with the key "key1", which will now be used in another key-value pair:
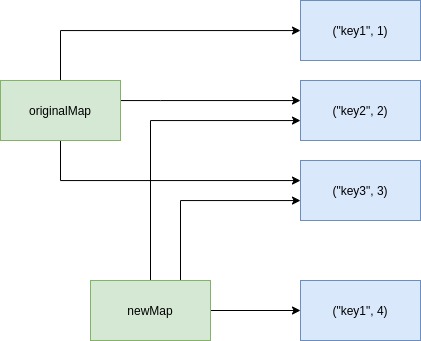
And this works because the compiler knows that since variables are immutable in our programming language, there’s no risk of something changing one of the key-value pairs referenced by our maps. This system, therefore, mitigates the “waste of memory” problem.
The second alleged problem and probably the most important one is the “waste of code”. So let’s say that you’re writing a very long piece of code tasked with sending a an accounting form to a very important government agency, and the code goes something like this:
// JavaScript
const accountFlows = {
inflows: 10,
outflows: 20,
net: -10,
};
calculateSomeStuff(accountFlows);
sendStatementToVeryImportantGovernmentAgency(accountFlows);
Some days later your boss comes yelling at you saying that you screwed up the accounting form you sent to the very important government agency. You have no idea what is going on, since all you did was to create a pretty simple program to send the data to said agency and do some calculations along the way. When you use the ultimate debugging tools to find out what is going on, you get the following code:
// JavaScript
const accountFlows = {
inflows: 10,
outflows: 20,
net: -10,
};
calculateSomeStuff(accountFlows);
// sendStatementToVeryImportantGovernmentAgency(accountFlows);
console.log(accountFlows);
// output
// { inflows: 10, outflows: 20, net: -20 }
And then you’re baffled to discover that the result is { inflows: 10, outflows: 20, net: -20 }. Some 4 hours and lots of coffee pods later you’re able to highlight the following code:
// JavaScript
const calculateSomeStuff = (flows) => {
// some 50 lines of code
flows.net = flows.net * 2;
// some more 50 lines of code
};
Some idiot forgot that the flows variable is an object, and in JavaScript objects are passed by reference, and not by value. Then your heart, now filled with ire, compels you to yell at the responsible just until git blame reveals that the culprit was you all along (ops).
Immutability guarantees, unless expressly written otherwise, that such problems will never happen. This kind of problem is known in the programming world as the Shared Mutable State Problem.
A state is a set of values that represent what is going one with a system at a given time. If you imagine a ball thrown in the air, it’s positional state can be represented by a vector containing the current time, it’s position, speed, acceleration and height. And the transition from one state to another can be described by Newton’s Laws of motion. The same thing happens in software: your program’s state can be represented by the values attributed to your program’s variables2, and the state transition law is described by your code itself.
In the example shown above, whe say that the state of the variable accountFlows was accidentally altered by the calculateSomeStuff function, which in this case was an undesirable behavior. Even though many techniques and design patterns were devised to avoid this kind of mistake, I believe that this kind of behavior should be avoided at the language level, thus freeing the programmer’s mind to focus on creating readable, correct and maintainable code.
You may think that Object-Oriented solves state manipulation in imperative programming by encapsulating state but this is just not the case. I may talk about it someday in one post, but since this is a quite long and complex argument I suggest you just watch this video.
Another advantage brought by immutability is that it automatically circumvents the problems created by parallel execution, so transforming a single threaded code into a multithreaded one is almost trivial in some functional languages:
// F#
open Microsoft.FSharp.Collections
let singleThreadedSeq = Seq.map veryCpuIntensiveFunction {1 .. 1_000_000}
let multiThreadedSeq = PSeq.map veryCpuIntensiveFunction {1 .. 1_000_000}
; Clojure
(def single-threaded-list (map very-cpu-intensive-function (range 1 1000000)))
(def multi-threaded-list (pmap very-cpu-intensive-function (range 1 1000000)))
Look ma! No mutexes!
And here is an 55 line simple example of Java parallelism3. Some other languages such as Python and Ruby4 don’t even offer threads due to the fact that they’re not thread safe (but to be fair, some funcional languages such as OCaml also don’t offer threads due to the Global Interpreter Lock).
The greatest evidence of the Immutability’s benefits is the fact that most popular modern imperative programming languages (Rust, Kotlin, Swift) offer immutability by default or strongly recommends it.
Higher-Order Functional Composition
The idea of functional composition is that programs are nothing more than a lot of functions arranged (composed) together to achieve the programmer’s goals.
In imperative object-oriented programming languages the center of the universe is the class, which is a mix state (attributes: values that change over time) and behavior (methods: ways of changing the object’s state or to make it interact with other objects). In this programming paradigm you’ll rarely see a function by itself on the wild.
# Python
class Animal:
position = 0
age = 0
alive = True
def walk(self):
self.position += 1
def bday(self):
self.age += 1
class Dog(Animal):
def bday(self):
super().bday()
if self.alive and self.age > 11:
self.alive = False
class Cat(Animal):
def bday(self):
super().bday()
if self.alive and self.age > 15:
self.alive = False
Even imperative object-oriented programmers know that parts of this kind of implementation (inheritance) is a bad idea, but it is clear in this example that functions (methods, to be more specific) are being used as just ways to encapsulate state change, so if we want to create a way to make our animals increase their position and age by one, the most simple way would be to do the following:
# Python
class Animal:
position = 0
age = 0
alive = True
def walk(self):
self.position += 1
def bday(self):
self.age += 1
def walk_and_age(self):
self.walk()
self.age()
# ...
So here classes are the main building blocks of our software.
In functional programming functions are the main building blocks of our programs (who would have guessed?):
// F#
type AnimalType =
| Dog
| Cat
type Animal =
{ Type: AnimalType
Position: int
Age: int }
let newAnimal animalType =
{ Type = animalType
Position = 0
Age = 0 }
let newDog () = newAnimal Dog
let newCat () = newAnimal Cat
let walk animal =
{ animal with
Position = animal.Position + 1}
let age animal =
{ animal with
Age = animal.Age + 1}
And afterwards, if we want to add a walk and age functionality, we just compose (combine) the walk and age functions into one:
// F#
// We're declaring that the function walkAndAge is the composition of walk and
// age functions.
let walkAndAge = walk >> age
// Another (very ugly) way to write it would be
// let walkAndAge animal = age(walk(animal))
Another instance of functional composition is the use of higher-order functions. For those unfamiliar with the concept, higher-order functions are functions that receive other functions as parameters or return functions as a result, and I must say that modern imperative programming languages also support this feature. Here are some examples:
- Function as parameter
In Python:
# Python
def greet_en(name):
return f"Hi! My name is {name}"
def greet_pt(name):
return f"Olá! Meu nome é {name}"
def greet(greet_fn, name):
return f"{name} says: {greet_fn(name)}"
# passing a function as a parameter to another function
greet(greet_en, "Jeff")
# 'Jeff says: Hi! My name is Jeff'
greet(greet_pt, "João")
# 'João says: Olá! Meu nome é João'
In F#:
// F#
let greetEn name = sprintf "Hi! My name is %s" name
let greetPt name = sprintf "Olá! O meu nome é %s" name
let greet greetFn name = System.String.Format ("{0} says: {1}", name, greetFn name)
greet greetEn "Jeff";;
// 'Jeff says: Hi! My name is Jeff'
greet greetPt "João"
// 'João says: Olá! Meu nome é João'
- Function as the result
// JavaScript
// divisibleBy returns a function which checks whether y is divisible by x
const divisibleBy = (x) => (y) => y % x === 0;
/* another way to write it would be:
const divisibleBy = (x) => {
return (y) => {
y % x === 0;
}
}
*/
// divisibleBy3 is now a function
const divisibleBy3 = divisibleBy(3);
divisibleBy3(7);
// false
const divisibleBy8 = divisibleBy(8);
divisibleBy8(24);
// true
In F#:
// F#
let divisibleBy x = fun y -> (y % x) = 0
let divisibleBy3 = divisibleBy 3
divisibleBy3 7;;
// false
let divisibleBy8 = divisibleBy 8
divisibleBy8 24;;
// true
Besides this toy examples, higher order functional composition is heavily used in functional languages in functions such as filter, map, fold, reduce and others. Here are some examples in F#:
// F#
let numbers = {1 .. 10}
let isOdd x = (x % 2) = 0
// the filter function receives a function that determines whether an element
// must remain in the sequence (isOdd) and the sequence of elements (numbers)
// and returns a sequence of all numbers that must remain in the sequence
Seq.filter isOdd numbers
// seq [2; 4; 6; 8; 10]
// the fold function "fold's" a sequence into a single value, accordingly to a
// accumulation function (in this case the function that multiply the
// accumulated value by the new element), an initial value for the accumulator
// and the sequence that must be folded, so in this case the result will be
// 1 * (1 * 2 * ... * 10)
Seq.fold (fun acc x -> acc * x) 1 numbers
// 3628800
// and then we can compose the already composed functions with one another
// seq [1; 2; ...; 10] -> seq [2; 4; ...; 10] -> 3840
numbers
|> Seq.filter isOdd
|> Seq.fold (fun acc x -> acc * x) 1
// if we want to turn everything into functions:
let filterOdd = Seq.filter isOdd
let multiplySeq = Seq.fold (fun acc x -> acc * x) 1
let multiplyOdds = filterOdd >> multiplySeq
multiplyOdds numbers
// 3840
These examples show that in the functional paradigm we treat functions as first-class citizens and make our programs mostly out of them. Even though some functional programming languages have Object-Oriented capabilities, even in those languages their object-oriented aspect is used mostly for interoperability and with immutability (Scala may be one of the exceptions to this rule). In most functional programming languages we tend to separate behavior (functions) from data (types or classes).
Some may think that dealing with functions instead of classes and methods may cause drop in productivity (where is my autocomplete after the .?) or code complexity (where should I put my functions and how can/must I access them?) but in those languages we use modules and namespaces to fill these gaps and structure our code.
So in my opinion, decoupling behavior and data and creating complex behavior based on the composition of simple behavior tends to produce code that is simpler and more readable than object-oriented imperative code.
Static Type Systems
Many programming languages have static type systems. Java has it. C# has it. Even C has it. So what is the big deal?
Usually, the functional programming languages that have static type system tend to have some variation of the Hindley–Milner type system which offers, amongst many features, parametric polymorphism, pattern matching and type inference. Allow me to show how this works.
Let’s say that we want to represent shapes (square, rectangle and circles) and we want some way to estimate their areas. If we’re using a programming language such as C++, we would do something like the following:
// C++
#include <iostream>
using namespace std;
class Shape {
public:
virtual float area() = 0;
};
class Square : public Shape {
public:
float side;
Square(float s) {
side = s;
}
float area() {
return (side * side);
}
};
class Rectangle : public Shape {
public:
float width;
float height;
Rectangle(float w, float h) {
width = w;
height = h;
}
float area() {
return (width * height);
}
};
class Circle : public Shape
{
public:
float radius;
Circle(float r) {
radius = r;
}
float area() {
return (3.1415 * radius * radius);
}
};
int main(void) {
Square s(5.0);
Rectangle r(2.5, 8.5);
Circle c(6.0);
cout << "Square area = " << s.area() << endl;
cout << "Rectangle area = " << r.area() << endl;
cout << "Circle area = " << c.area() << endl;
return 0;
}
// output:
// Square area = 25
// Rectangle area = 21.25
// Circle area = 113.094
We can see many things from the code above. The first of all is all the noise derived from types annotations. For instance:
// C++
class Circle : public Shape
{
public:
// Here we tell the compiler that the radius variable is float
float radius;
Circle(float r) {
// Since we're making radius = r, it is obvious that r must be float
// (since radius is float), so why we must tell this to the compiler?
radius = r;
}
// And since radius is float, the result of the product of
// 3.1415 * radius * radius must be float, therefore this function must
// return float, so why we must tell this to the compiler?
float area() {
return (3.1415 * radius * radius);
}
};
This kind of redundant type annotation pollutes our code everywhere. Other more fundamental problem is the fact that we needed to create 4 full classes to express the idea that circles, rectangles and squares are all shapes and have areas.
In a statically typed functional programming language such F# we could implement the same program as this:
// F#
type Shape =
| Square of side: float
| Rectangle of width: float * height: float
| Circle of radius: float
let area shape =
match shape with
| Square side -> side * side
| Rectangle(width, height) -> width * height
| Circle radius -> 3.1415 * radius * radius
let s = Square 5.0
let r = Rectangle (2.5, 8.5)
let c = Circle 6.0
printfn "Square area = %f" (area s)
printfn "Rectangle area = %f" (area r)
printfn "Circle area = %f" (area c)
// output:
// Square area = 25.000000
// Rectangle area = 21.250000
// Circle area = 113.094000
The change in the code quantity and quality is very noticeable: from 62 lines of pure C++ caos to 18 lines of readable and clean functional bliss. So lets unpack what is going on en each part of the code above, starting with the types definition:
// F#
type Shape =
| Square of side: float
| Rectangle of width: float * height: float
| Circle of radius: float
The type Shape is what we call Discriminated Union type. It tells the compiler that a value of the type Shape can assume three possible mutually exclusive values: Square, Rectangle or Circle. Then we describe what are the parameters of each possibility: Squares “store” one value of the type float which will represent it’s side size; Rectangles “store” two values of the type float, one representing it’s width and another it’s height; Circles “store” one value of the type float to represent it’s radius.
This type of definition is extremely flexible, allowing you to have some crazy combinations such as:
// F#
type Color =
// case with no field
| Red
| Green
| Blue
// case with fields in the same type
| Other of red: int * green: int * blue: int
type Fruit =
| Banana
| Pear of brand: string
// case with different types and using another user-defined type
| Tomato of weight: float * color: Color
And when we want to use the types we only need to use the cases as constructors:
// F#
// for cases with no field we just use it as a constructor with no parameters
let red = Red
// for cases with one field we can use it as a simple function
let thePear = Pear "Tasty"
// for cases with fields we pass them inside a tuple
let cyan = Other (0, 255, 255)
let superTomato = Tomato (33.4, red)
Notice that the only place in which we needed to use type annotations was in the declaration of the types themselves. Here (and in many functional statically typed languages) the compiler is capable of inferring the type of the variables that we create by how they are created and how we use them. This is what is called type inference.
In the second part of the code we leverage one of the superpowers of this kind of type system, the pattern matching:
// F#
let area shape =
match shape with
| Square side -> side * side
| Rectangle(width, height) -> width * height
| Circle radius -> 3.1415 * radius * radius
In pattern matching, as the name says itself, the compiler tries to fit the variable to a specific pattern of the expression, and if the match is successful it will evaluate the expression associated with it. So when shape is equal to c the function will see whether it can match Circle 6.0 with Square side, since Square != Circle it will try the following branch, since Rectangle != Circle it will try the following branch, and since c has the constructor Circle and only one field, which can be bound to radius, it will do just that, binding 6.0 to radius and evaluating the 3.1415 * radius * radius expression.
Another very interesting thing that is happening here is that it wasn’t necessary to declare neither the type of shape nor the return type of the area function, since the compiler once again used type inference to determine both these types.
Just writing about this kind of stuff gives me goose bumps.
By now some dynamic languages aficionados might be thinking: “This is completely useless. I thought that by now everyone already learned their lesson that static types are a waste of time and only decrease productivity.”, and to answer that I make two points: first by saying that there are dynamically typed functional languages (such as clojure, elixir) if using static types is a deal breaker for you, and secondly by saying that the combination of type inference and static types greatly increases one’s long term productivity by drastically reducing the frequency some classes of bugs without the necessity of extensive and repetitive type annotation.
The first class of bugs that is avoided by such combination is the ones added during refactoring. Let’s say that we modify the shape type to include the Ellipse shape:
// F#
type Shape =
| Square of side: float
| Rectangle of width: float * height: float
| Circle of radius: float
| Ellipse of a: float * b: float
Now all functions that uses the Shape type must be refactored to take into account the new case, including our area function. But let’s say that you end up forgetting to refactor this function and tried to compile the project. The following message would appear in your log:
Warning FS0025: Incomplete pattern matches on this expression. For example, the value ‘Ellipse (_, _)’ may indicate a case not covered by the pattern(s).
This is the compiler informing us that the shape parameter can assume a value for which we didn’t prepare our area function. Experienced programmers know that this is a very common type of bug that tends to be introduced in large systems while they’re being refactored and having the help of the compiler in this task is, in my opinion, of great value.
This kind of problem is usually circumvented in dynamically typed languages with widespread unit testing, but I’m of the opinion that the more tools we can use to help us write correct code the merrier, so using statically typed functional programming languages that support type inference helps me write and modify code faster, with less bugs and less fear therefore being more productive in the long run.
Some other languages have even more powerful type systems, such as Haskell, that has what is called typeclasses that work similarly to interfaces. For example:
-- Haskell
-- Defining the type fruit, which is a discriminated union of banana and apple
data Fruit = Banana Float | Apple Float deriving (Show, Eq)
-- Defining the type plate, which is a discriminated union of pasta and salad
data Plate = Pasta Float | Salad Float deriving (Show, Eq)
-- We want to create a function that receives either a fruit or a plate and
-- reduces it's weight by a "bite size", but fruit and plate are different types
-- How can we create such function?
-- We start by defining the typeclass edible, which is like an interface that
-- says that any type that implements it must implement the function eat, that
-- receives an element of it's own type, a value of type float and returns
-- another element of it's own type
class Edible a where
eat :: a -> Float -> a
-- Then we implement the "interface" edible for the fruit type
instance Edible Fruit where
-- Declaring the function many times with different constructors for a given
-- parameter is one way of doing pattern matching in haskell
eat (Banana weight) biteWeight = Banana (weight - biteWeight)
eat (Apple weight) biteWeight = Apple (weight - biteWeight)
-- And we do the same thing for the Plat type
instance Edible Plate where
eat (Pasta weight) biteWeight = Pasta (weight - biteWeight)
eat (Salad weight) biteWeight = Salad (weight - biteWeight)
-- Here we're defining a generic function which will apply the eat function
-- to any list of values that are of a given type that "implements the
-- interface" Edible
eatEverything :: Edible a => [a] -> Float -> [a]
eatEverything xs w = map (\x -> eat x w) xs
-- Now we can use the eat function for different types: welcome to polymorphism
-- in Haskell (there's no simple way of doing this in F# as far as my knowledge
-- goes).
eat (Banana 10.0) 5.4
eat (Salad 22.4) 4.7
-- output
-- Banana 4.6
-- Salad 17.7
-- And use the eatEverything in lists of various types
eatEverything [Banana 10.0, Apple 11.6, Apple 4.4] 1.0
eatEverything [Pasta 10.0, Pasta 11.6, Salad 4.4] 2.2
-- output
-- [Banana 9.0,Apple 10.6,Apple 3.4]
-- [Pasta 7.8,Pasta 9.400001,Salad 2.2]
Unfortunately choosing Haskell’s type classes brings with it a bunch of downsides too, such as the Haskell’s Record Problem.
Some other languages, such as Idris have even more powerful type systems, such as the dependent types system, in which the type system itself is capable of representing things such as a list size and forbidding access to elements outside the said list, but that is beyond the scope of this post.
Pure Functions
A function is considered pure if it has both the following properties:
- It always returns the same result for the same input
- It produces no side effects
It is a very simple and yet very powerful concept. Since both these properties have relations with the concept of side effect, let’s first understand it’s meaning.
Take these two functions:
// JavaScript
const add1 = (a, b) => {
const result = a + b;
return result;
};
const add2 = (a, b) => {
const result = a + b;
writeInDB(result);
return result;
};
One can see that every time you use add1 to sum numbers the only thing that happens is the computation of summing up the values of a and b and returning the result of this computation, whereas the function add2 also writes in the database the result of the computation before returning it. The act of writing in a database changes the “state of the world” every time this function is executed and the act of changing the state of anything that is persistent outside the scope of the function is called a side effect. Others examples of side effects are writing of reading files, printing data on the screen, sending or receiving signals, changing attribute of objects (state), among others.
Side effects, as you can imagine, are an integral part of any useful software (some would say that they are the most important part) but they can be very dangerous.
Here’s an example of how dangerous they can be: say that you’re working on a very large project and you’re consuming a library that some other coworker or a third-party company offered you. You’re working at a bank and you’re trying to write a function that summarizes how much money the clients of a given bank agency have deposited on their accounts. The library that you were given offers, amongst many other functions, the following one:
// JavaScript
getFinancialStatement(clientId, dbConnection);
You, a very productive agile developer, skips the function’s documentation and goes straight to the interactive environment to test the candidate function to see what comes in the other end:
// JavaScript
getFinancialStatement('1234', dbConnection);
// output
// {
// clientId: '1234',
// checkingAccountId: '555-123',
// checkingAccountAgencyId: '987',
// checkingAccountBallance: 99.85,
// ...
// }
And then your head goes: “Jackpot!”. You then go ahead and implement something like:
// JavaScript
getAgencyClientsBalance(agencyId, dbConnection) {
let clients = getAgencyClients(agencyId);
let balance = 0;
for (let client of clients) {
balance +=
getFinancialStatement(client.id, dbConnection).checkingAccountBallance;
}
return balance;
}
Then, with all your agility you mock the call to all database dependent functions, pass all tests and vois-la, you’ve just implemented the feature and pushed it into production.
The next day you get to your chair just to find out that your presence is urgently requested at the human resource’s office. What happened?
Well, what happened is that the getFinancialStatement implementation follows something like this:
// JavaScript
const getFinancialStatement = (clientId, dbConnection) => {
const client = getClient(clientId, dbConnection);
let financialStatement = getRawFinancialStatement(client, dbConnection);
const fee = getClientFinancialStatementPrintingFee(client, dbConnection);
let financialStatement = {
...financialStatement,
checkingAccountBallance: financialStatement.checkingAccountBallance - fee,
};
updatedFinancialStatement(financialStatement, dbConnection);
return financialStatement;
};
The catch that costed this specific developer’s job was that this function automatically updated the client statement with a fee for each time the statement is printed (maybe that’s why the first time he tested this function the ballance was 15 cents shy of $100). And that’s why functions with side effects are undesired, they may encapsulate behavior that is not evident and might be dangerous. Pure functions doesn’t suffer from this problem since they can’t perform side effects.
Documentation (both the writing and the reading thereof) and the disciplined usage of design patters may mitigate this problem, but what most functional developers do is separate the impure from the pure functions. Some languages, such as Haskell and Purescript go all the way and allow only pure functions (side effects are implemented trough IO Monads). Other languages allow impure functions and developers use the language’s convention of marking their names to signal their impurity.
; Clojure
(defn pure-function [a b] (+ a b))
; clojure uses the * to signal impurity
(defn impure-function* [a b dbConn] (...))
Even though most functional programming languages provide no way of knowing whether a function is pure or impure without looking at the code, most software written in functional programming languages tend to use architectures that minimizes, concentrates and highlight functions with side effects, such as the hexagonal architecture.
Pure functions are easier to reason about, to combine, to test, to debug and to parallelize since they have no state or side effects, and using functional programming languages facilitates and incentivises their usage
Lazy Evaluation
Here we got to the part that even though I’m able to appreciate the advantages of the feature, I don’t have a deep understanding of how it works or of all the ways in which it can be used, so if you’re interested in learning more about it google can provide you with better material than this section. Now that we put the disclaimer out of the way let’s talk about lazy evaluation in functional programming languages (I’m not aware of any imperative programming languages that heavily leverage this feature).
Let’s start by implementing the good ol’ Fibonacci sequence. As many of you may know, it’s given by the following function:
And the classical imperative implementation of this function usually goes as follows:
const fibSeq = (max) => {
if (max === 1) {
return [1];
}
if (max === 2) {
return [1, 1];
}
const result = [1, 1];
for (let i = 3; i <= max; i++) {
const f = result[result.length - 1] + result[result.length - 2];
result.push(f);
}
return result;
};
fibSeq(10);
// output
// [
// 1, 1, 2, 3, 5,
// 8, 13, 21, 34, 55
// ]
Even though this is an extremely naïve implementation of this function it is pretty straight-forward. But let’s implement this in Haskell and see what we can get:
-- Haskell
-- This is how composition is done in Haskell, just like in math
-- h(g(f(x))) = h . g . f (x)
sumLastTwo = sum . (take 2) . reverse
fibSeq 1 = [1]
fibSeq 2 = [1, 1]
fibSeq n = lastFib ++ [sumLastTwo lastFib]
where lastFib = fibSeq (n - 1)
fibSeq 10
-- output
-- [1,1,2,3,5,8,13,21,34,55]
But here’s a funny thing: programming languages with lazy evaluation allows us to write infinite sequences! Here’s an example:
-- Haskell
theInfiniteSequence = [1 ..]
This is an example of a sequence that starts at 1, increasing by one and never terminating. This is the first example of the power of lazy evaluation: the ability of representing infinite data structures without exploding our memory (in fact using almost no memory, since the only thing stored is the thunk representing the expression util the expression is evaluated).
Then you might say “La-di-da! Congratulations, you can now represent useless stuff!”, but allow me to show you the following:
-- Haskell
-- source: https://mail.haskell.org/pipermail/beginners/2016-June/016969.html
fibs = 0 : 1 : [ n | x <-[2..], let n = (fibs !! (x-1)) + (fibs !! (x-2))]
First a quick Haskell syntax explanation:
- List concatenation
-- Haskell
xs = 1 : 2 : 3 : []
xs
-- output
-- [1,2,3]
- Accessing elements from lists
-- Haskell
xs = [0 .. 10]
xs !! 3 -- get element at index 3
-- output
-- 3
-- Haskell
-- evenNumbers is equal to x where x is in the positive numbers and the
-- remainder of its division by two is zero (just like in maths)
evenNumbers = [x | x <- [1..], rem x 2 == 0]
take 10 evenNumbers
-- output
-- [2,4,6,8,10,12,14,16,18,20]
-- perfectSquares is equal to a sequence of n's where n is equal to the square
-- of x and x is in the positive numbers (just like in maths)
perfectSquares = [n | x <- [1..], let n = x * x]
- Mixing it all together
-- Haskell
-- fibs is the concatenation of the numbers 0, 1 and the list which is the sum
-- of the last two elements of the same list
fibs = 0 : 1 : [ n | x <-[2..], let n = (fibs !! (x-1)) + (fibs !! (x-2))]
This, my angry friend, is the infinite Fibonacci sequence. Each element of this sequence will be evaluated only when it’s value is absolutely necessary:
-- Haskell
-- print the 10th fibonacci number, which will make the runtime evaluate the
-- `fibs` sequence up to the 11th element
fibs !! 10
-- output
-- 55
-- print the first 12 elements of the sequence, which will make the runtime
-- evaluate two more elements from the list
take 13 fibs
-- output
-- [0,1,1,2,3,5,8,13,21,34,55,89,144]
And throughout your code you could use the fibs name knowing full well that no unnecessary number would ever be calculated once and no necessary number would be calculated twice.
There are many other advantages of Lazy Evaluation, but there are also many disadvantages, most notably a somewhat unpredictable memory and processor usage, and for some use cases this is a deal breaker (time sensitive and memory restricted applications).
Haskell was created almost as a laboratory for lazy evaluation5, which was a trendy CS research topic at the time of its creation, therefore it is an opt-out lazily evaluated6 programming language, meaning that unless explicitly declared otherwise, the runtime execution will follow this directive. This means that even though it is possible to write Haskell code that mitigates most of the pitfalls of lazy evaluation, this takes experienced developers and a lot of mental effort.
Nowadays most programming languages that offers lazy evaluation offer it in a opt-in basis. Here’s an example in F#:
// F#
// All elements on this list will be evaluated immediately
let strictList = [1 .. 10];;
// output
// val it : int list = [1; 2; 3; 4; 5; 6; 7; 8; 9; 10]
// 'Seq's in F# are lazy by default, so the elements on this sequence will be
// evaluated only when they're needed. Notice the difference in the REPL output
// for both statements
let lazySeq = {1 .. 10};;
// output
// val lazySeq : seq<int>
Therefore I like using opt-in lazy evaluation in functional programming languages to represent infinite data structures and computations that might not be needed or might be used more than once in a program.
Tools do matter
There’s also an idea that keep hearing over and over again. This idea is that “The tool doesn’t matter, only how you use it to solve the problem.”, but I strongly disagree with this statement. A hammer has two interfaces: one for the nail and one for the user, and different hammers, even thought most of them can get the job done, can have radically different user interfaces (metal, wood, plastic, foam). The same is valid for programming languages: most languages can solve most problems, but each programming language has a different user interface, with some being more pleasant to use than others, offering more confidence than others, offering more safety than others.
The analogy goes even further: every sushiman must have it’s own knife because the way he uses its knives mold them through time to be best used in that way (and letting other people use it will make them worse for the owner), but at the same time the type of knife used by the sushiman will heavily influence his cooking technique, since every type and brand of knife has their own virtues and vices. The tool molds and is molded by it’s user. In my experience the same happens for programming languages: the usage of a specific programming language will mold it (the user will extend it by creating scripts, libraries, blog posts, etc which will influence the evolution of the language itself) and the language will mold the user by influencing the way he thinks about problems, therefore creating a virtuous or vicious cycle between the user and the language.
So, in my opinion, the choice programming language do matter when you’re trying to solve problems, and denying that is foolish and dangerous, therefore assuming this to be true I’d rather let my brain be molded by the use of programming languages that are more compatible with the way humans think and describe problems instead of forcing my brain to think like a machine.
It’s not (only) a popularity contest
Another argument that many people use to try to convince me to rejoin the dark side is that since imperative programming is more popular (the “Google uses it” argument) this is either an indication that those languages are better (therefore their widespread usage) or due to the fact that more people use it the language becomes better due to the increase availability of libraries, books, posts etc.
I agree to a certain point that quantity has a quality all its own, but let’s think about it: unless you’re Google, it’s safe to say that you’re probably implementing some boring enterprise stuff or a very common product, such as a RESTful web system, a CMS of some sort or some linear combination of both. In this case, how many libraries do you really need to implement your system? Provided that the ones you need do exist and are mature enough, does it make a difference whether there are another 10.000 or 10.000.000? My point here is that as long as you don’t pick a niche programming language, there’s probably a big enough community and amount of libraries at your disposal, and since you’ll probably be dedicating 90% of your programming time to the language itself (solving business problems and not technical problems) I prefer to let the language help me instead of needing to do stack-overflow-oriented-programming all the time.
Conclusion
As Mark Seemann argues in the talk Functional architecture - The pits of success, my experience with functional programming languages and architectures have been teaching me that the benefits of functional programming languages more than outweighs its disadvantages. Functional programming makes it harder to make bad software decisions, putting you in a pit of success.
Learning new paradigms and architectures is no easy feat. I’ve been at it for almost one and a half years now and I’m nowhere near having tha same proficiency in the functional paradigm as I once did in the imperative one, but even half way through this journey I can already see the enormous improvements on the quality of the software that I’ve been shipping.
Addendum
I had the honor to have this post be peer reviewed. You can see their comments about each part of the post here and the review stream here. Thank you for the feedback!
-
If you’re not familiarized with the Lisp syntax you’ll probably be more confused than elucidated by this example, but I hope you got the idea in the previous examples. ↩
-
You can say that the state of the universe is also a part of your program’s execution state, but I chose to omit this for simplification purposes. ↩
-
Trigger warning. ↩
-
At least the last time I checked. I heard this would be a non-issue in the near future but I don’t know how far this feature has progressed. ↩
-
I heard this once in a talk by one of the Haskell creators, but wasn’t able to remember the name of the fellow doing the talk nor the recording of the talk itself, so take this with a grain of salt. ↩
-
It is actually non-strict, to be exact. ↩